Pulling Data Via An API In Python
What Is an API?
An API, or Application Programming Interface, is a powerful tool that enables organizations to access and interact with data stored in various locations in real time. In other words, APIs allow different computer programs to communicate with each other seamlessly. For example, your business may have accounting software, a CRM, a time tracking application, a payroll system, and an inventory tracking app. Likely, you’ll want to pull your organization’s data from all of these sources and bring it together into one place so that you can do more advanced analytics. You may want to answer questions like “What is the revenue per employee per project?” (accounting + time tracking). Or what is my average sale amount by industry? (accounting + CRM). APIs allow quick and accurate access to your data that’s stored in these various places.
Why APIs Matter
Two key features that distinguish exceptional data strategies from average ones are automation and real-time analytics. APIs deliver both of these crucial features.
Automation: APIs allow programmers to write scripts that automatically retrieve data and integrate it into your organization’s reports, dashboards, applications, and algorithms. This level of automation streamlines processes, eliminating the need for manual data entry, saving time, and ensuring accuracy.
Real-Time Analytics: APIs offer real-time data pulling, ensuring that reports, dashboards, and algorithms always update as new data flows into your data source. This instantaneous access to data empowers organizations to make decisions based on the most current information.
Taking Advantage of APIs for your Organization
Boxplot can pull your data from the various apps that your business uses. From there, we can visualize data, write data science algorithms, or automate business processes. Set up a call with us to chat about your project.
If you want to follow an example of implementing an API in Python, keep reading below.
Pulling Data from an API in Python
In this blog post, we’ll focus on pulling data from an API using Python, but it’s important to note that various methods are available for data retrieval, including R, VBA (Excel), Google Sheets, Tableau, PowerBI, JavaScript, and more. Additionally, while we’re discussing data pulling in this post, APIs can also be used to push (insert) data into a database, although we won’t cover that here.
Every API is unique, and mastering any specific API takes time. The example in this post focuses on a basic API to illustrate the main concepts.
Getting Started: Pulling Data in Python
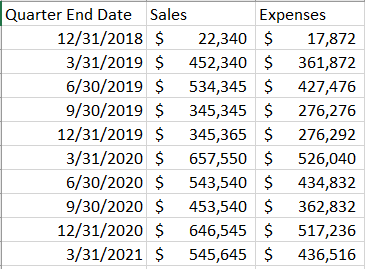
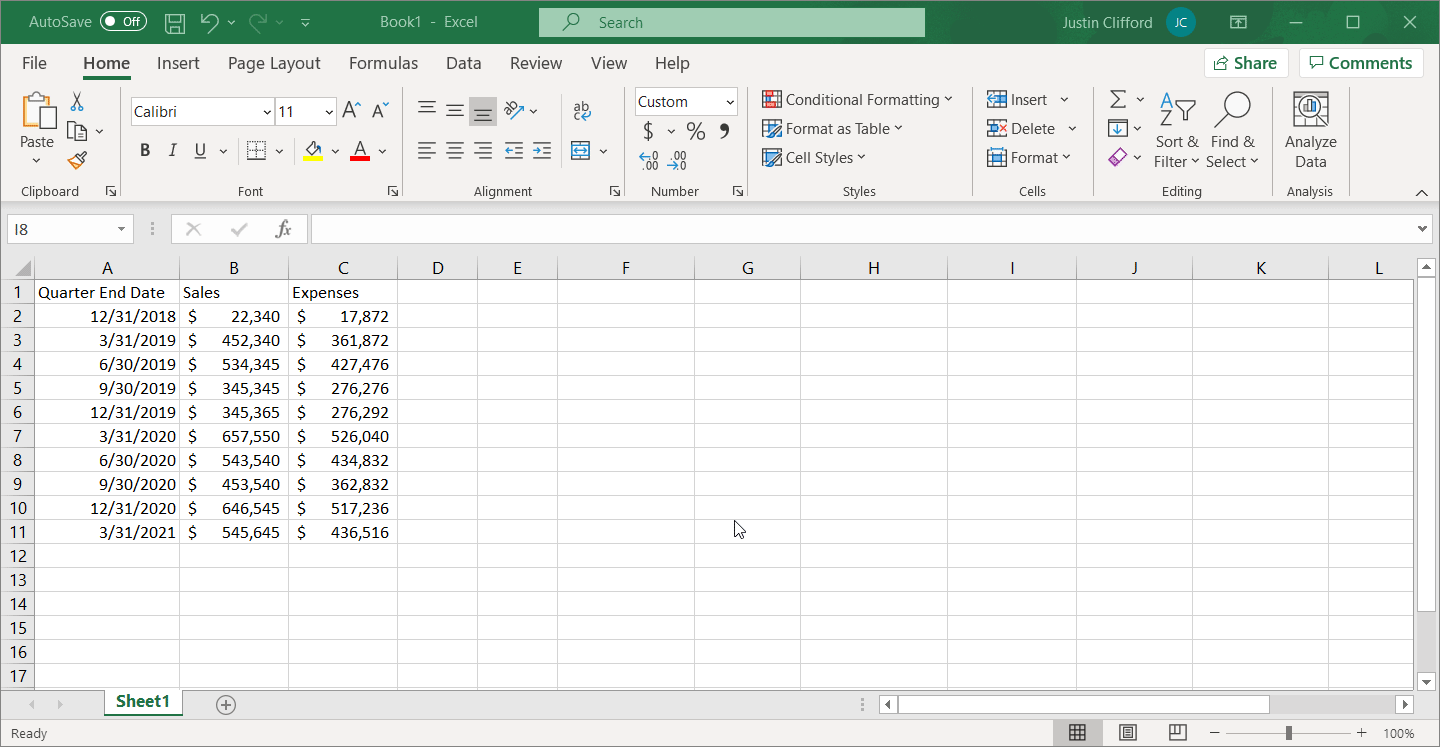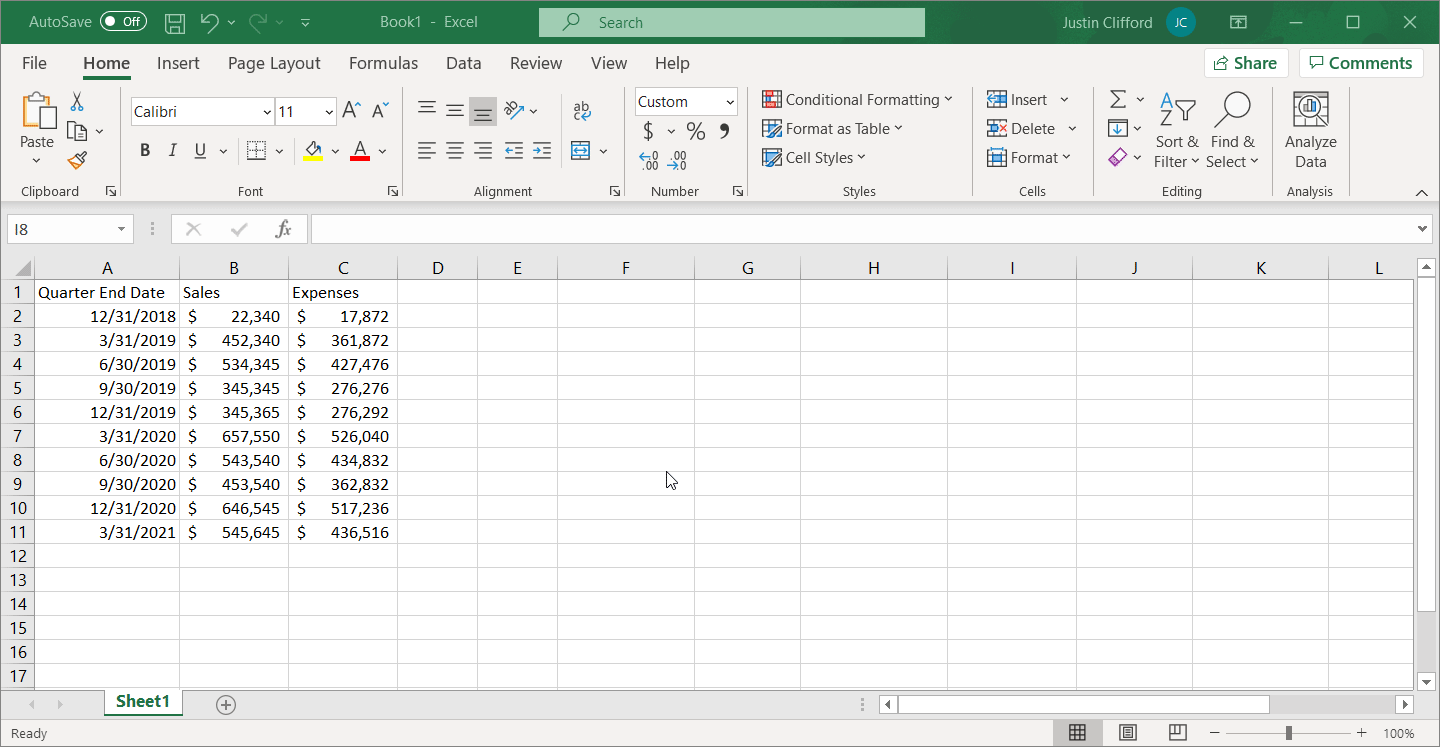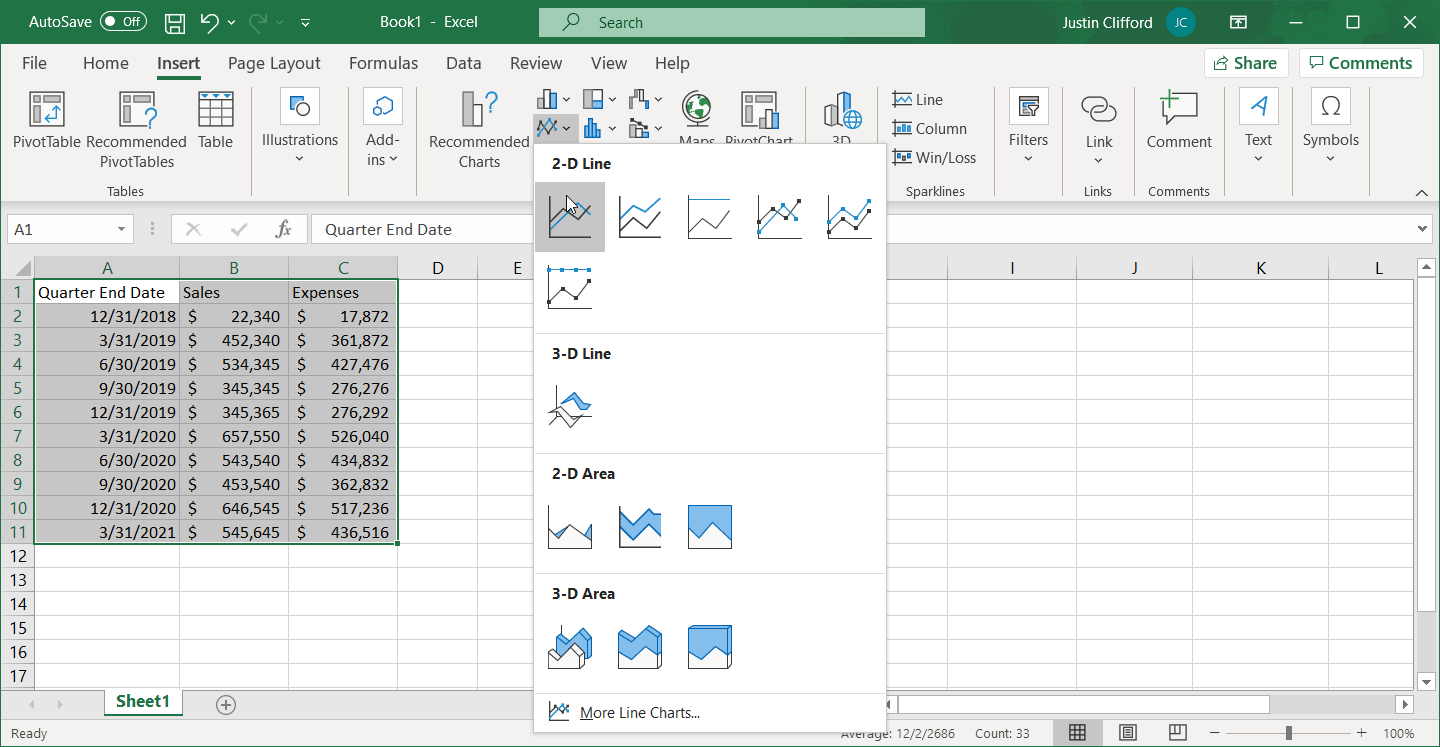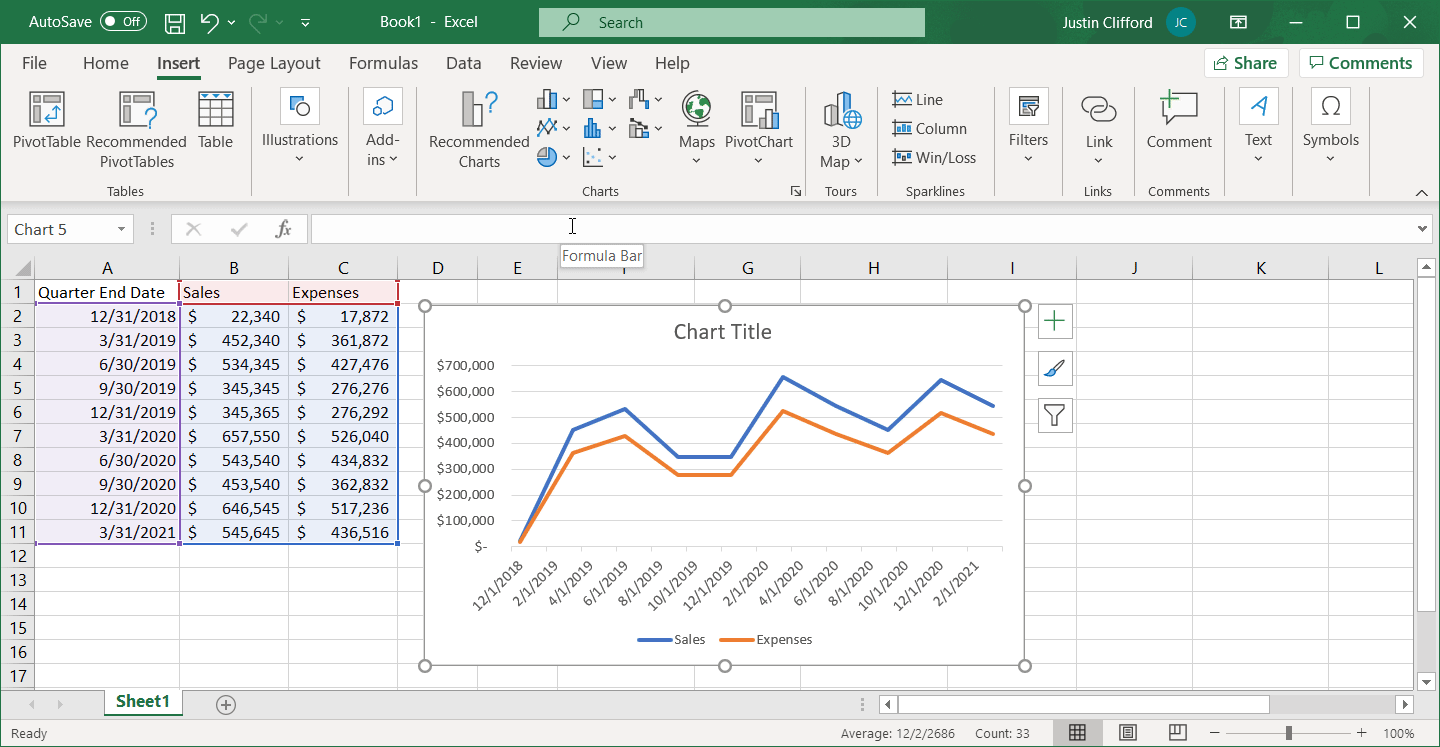
Let’s do a simple example of pulling data in Python using an API. In this example, we’ll be pulling unemployment data from the Federal Reserve of St. Louis (FRED) website using their API; if you want to follow along with me the URL of the dataset is accessible here, and general information on the API is here.
In order to pull data from an API in Python, you first must obtain credentials. If you’re using a payware product’s API it’s likely that you’ll be provided with credentials to access the API upon purchasing access (credentials for a payware API are usually a username/password combination). But for an open-source API ―such as the one in this tutorial― you’ll usually get an API key, which in this case is a 32-character alphanumeric string. To get an API key from FRED, first create a FRED account for yourself (it’s free) and then generate a key by visiting this page. Then, fire up your preferred Python IDE and copy and paste the API key as a string variable into a new Python program; you will need that key in a second.
Now let’s code. The first thing you’ll need is to import ‘json’:

As a brief aside, json (JavaScript Object Notation) is a data formatting style that creates key-value pairs in a way that is easy for humans to read, similar to a Python dictionary (in fact, one step of using the API is converting json data to a Python dictionary, as we’ll cover later on). When you read the data in, it comes to us in json format, which is why we’re using the json format here.
We also need to import a package called ‘requests’. When you pull data from an API, what’s going on under the hood is that your program is making a request to the API’s server for the specified data set, and this ‘requests’ package allows us to do just that.

Next, you must build the URL that you’ll use to access data series. In the FRED API, the general form of this URL is: https://api.stlouisfed.org/fred/series?series_id=GNPCA&api_key=abcdefghijklmnopqrstuvwxyz123456&file_type=json
but it will be different for every API. To customize this URL for your usage, you must first replace ‘GNPCA’ with the series ID of the series you’re interested in pulling. In our example, the series ID is ‘UNRATE’, but you can find the series ID of any FRED data series by going to its page and looking at the code in parentheses next to the series name:
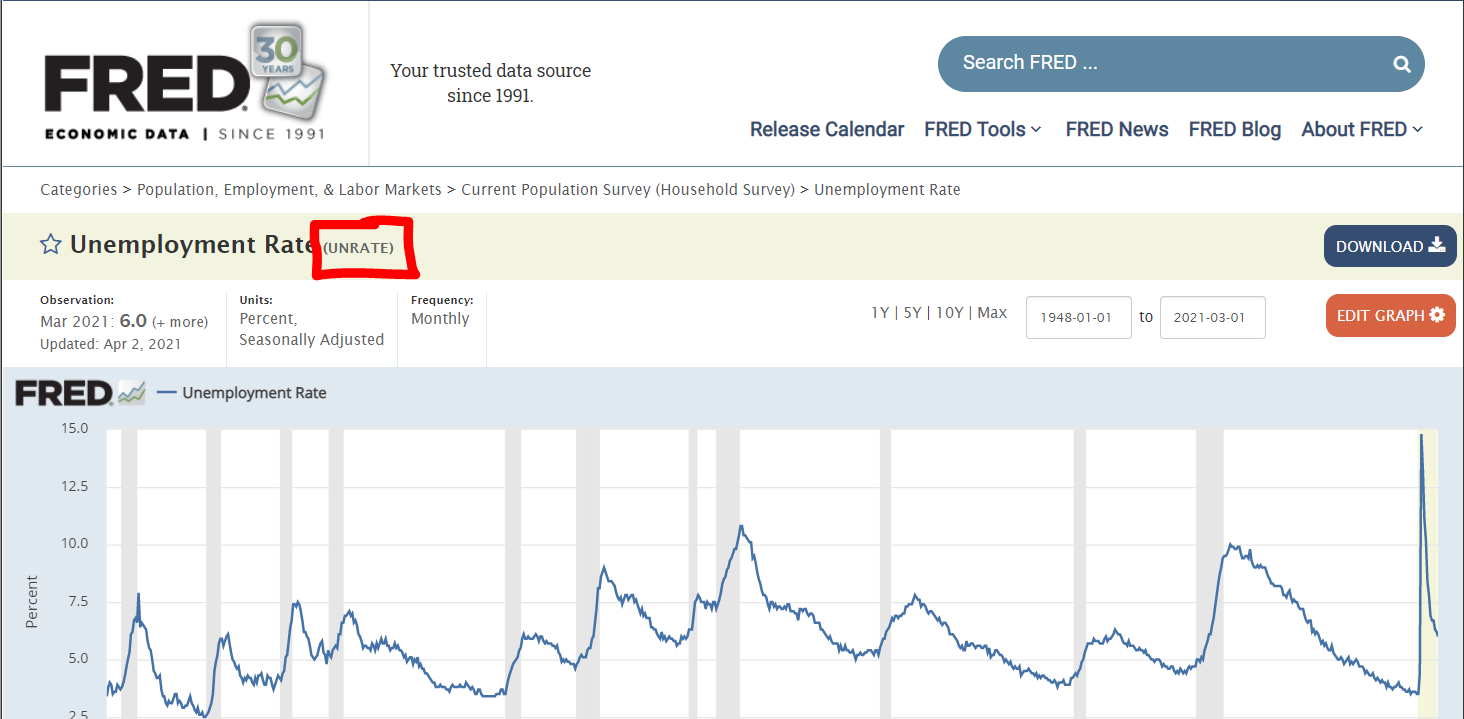
Then, replace the API key in the URL (abcdefghijklmnopqrstuvwxyz123456) with your own API key. Note that the final parameter in this URL is file_type=json, which allows us to pull the data series into json formatting. And that’s it; overall, if my API key were ‘abcdefghijklmnopqrstuvwxyz123456’, my completed URL would be:
https://api.stlouisfed.org/fred/series?series_id=UNRATE&api_key=abcdefghijklmnopqrstuvwxyz123456&file_type=json
What do you do with this URL now that it’s completed? This is where the requests package comes in. The requests package has a method called get() that makes the request to the API’s server and pulls data into json format. Saving the output of this get() method to a variable allows us to customize the data that is pulled, which is exactly what you want to do. Doing so will return a variable in json format, and so if you call the json() method on this variable, the data will be shown. So, overall, our code to pull data from the API into Python and show the output looks like this:
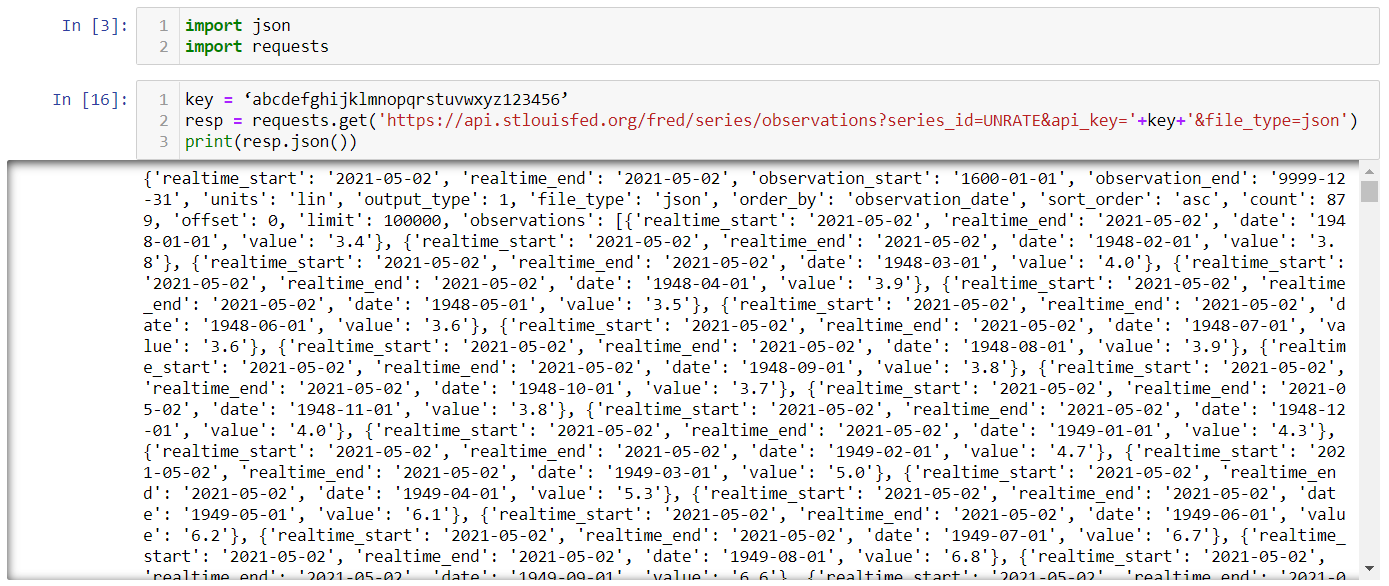
(of course, remember to swap in your own API key for the ‘key’ variable).
From there, this json object is queryable and iterable just like a regular Python dictionary. For example:

And you can see from the output of resp.json() that

contains the actual data series.
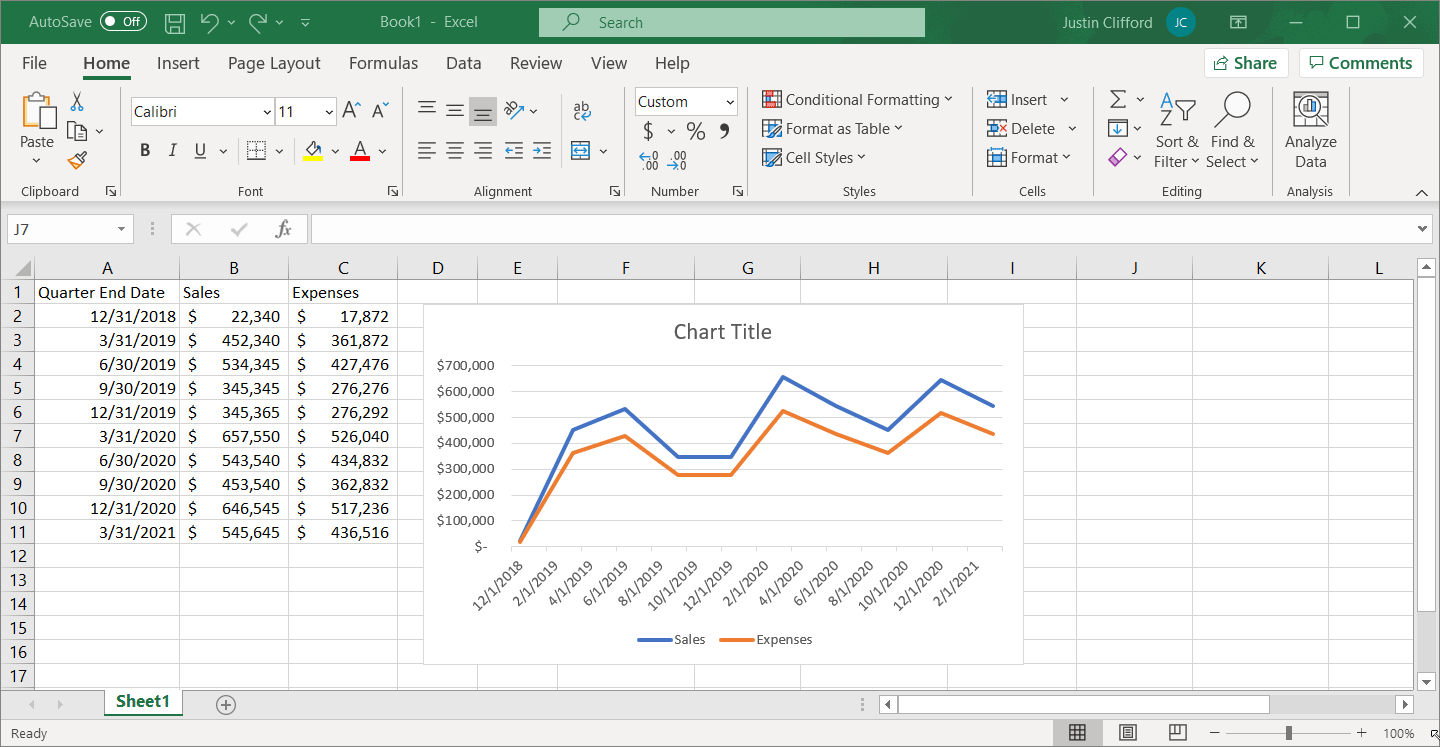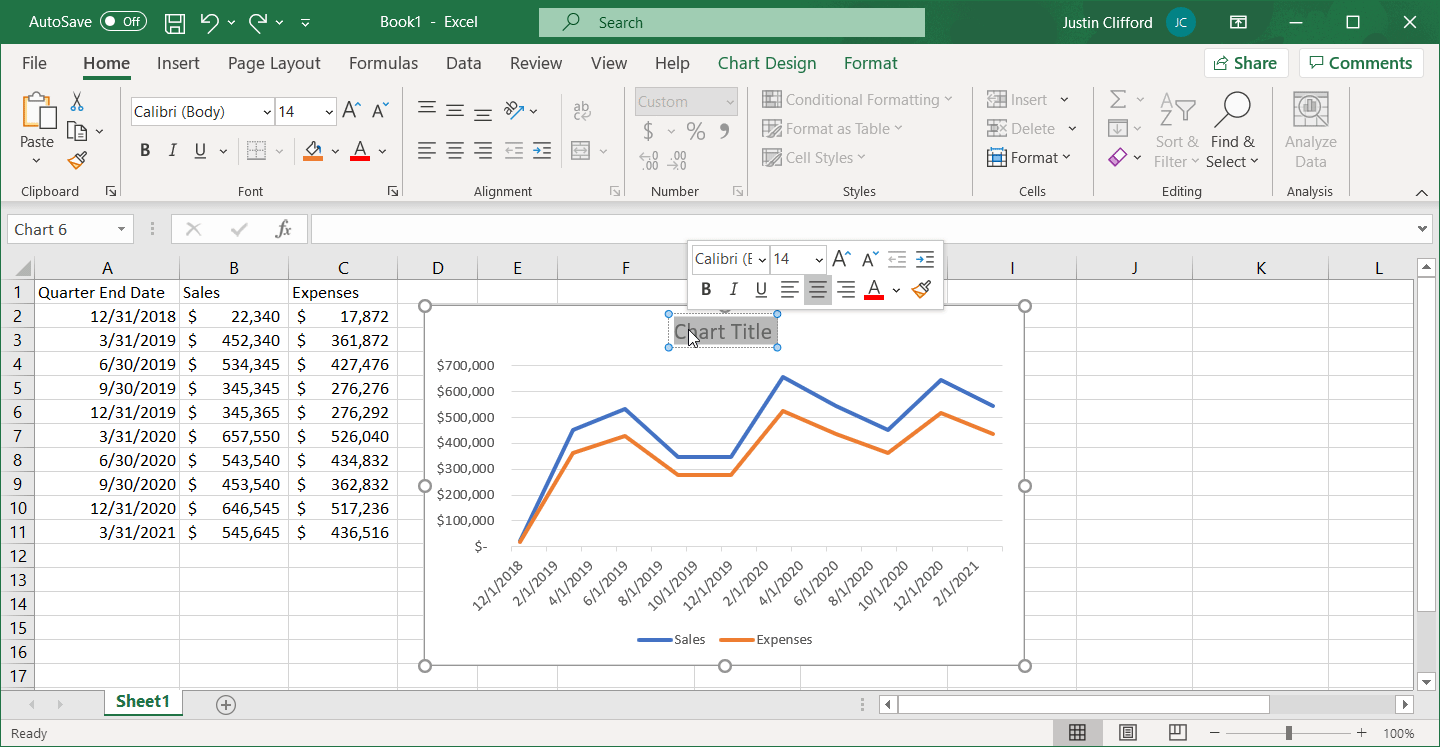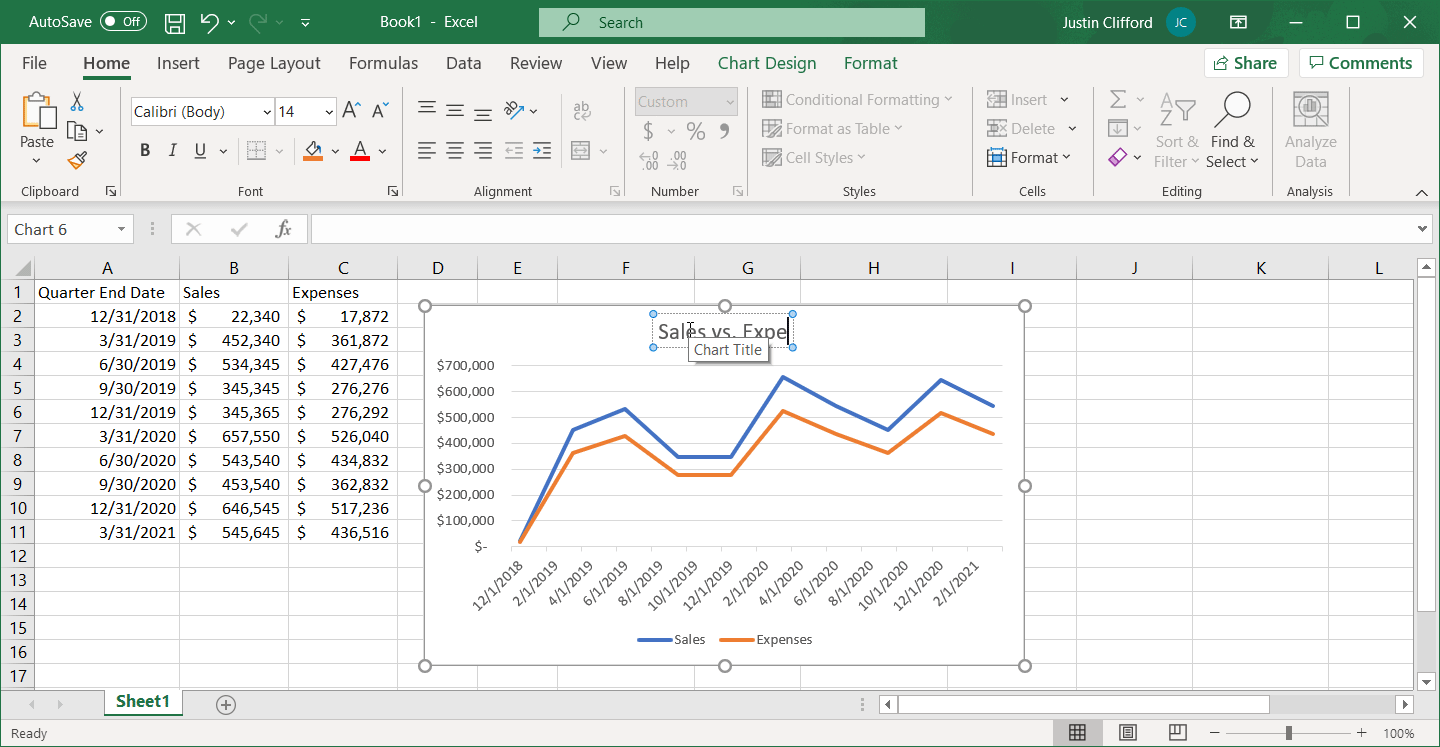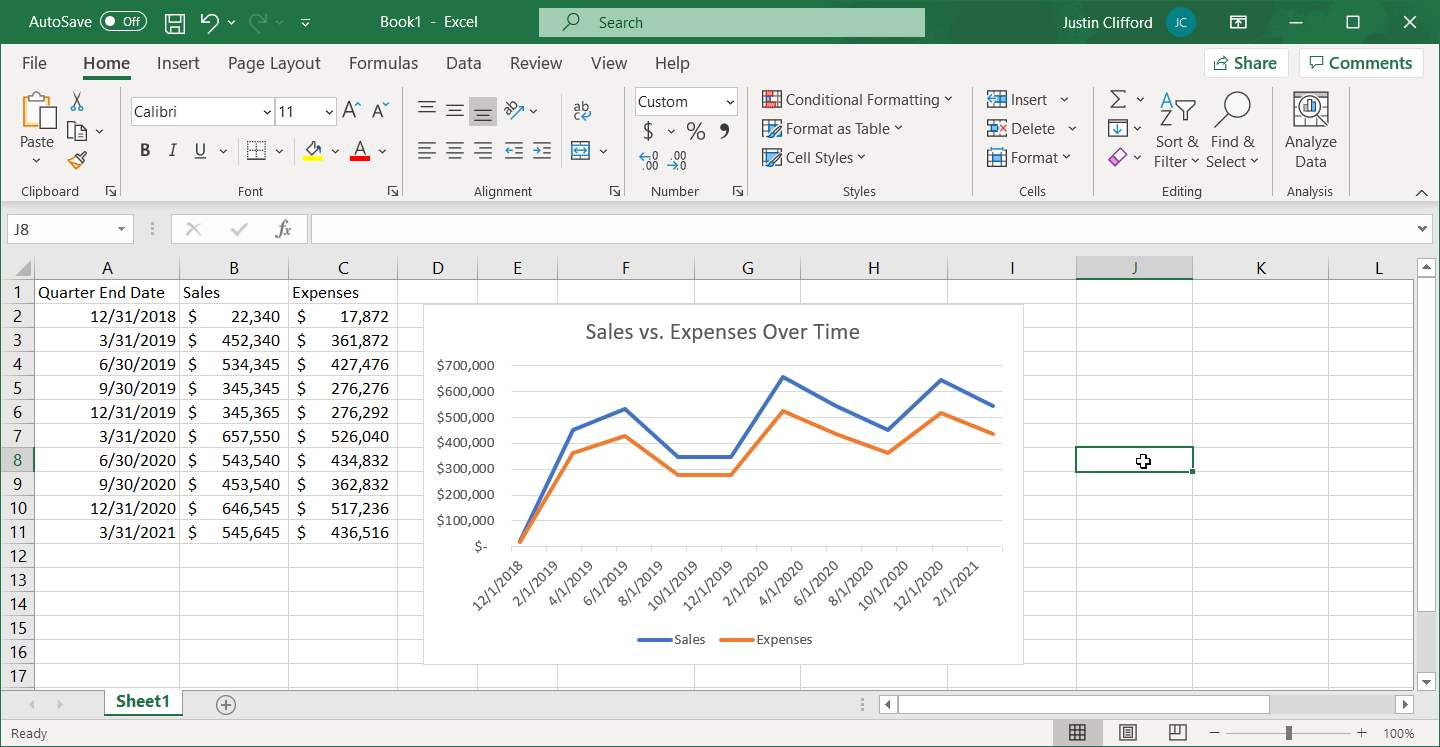
By creating a report, dashboard, algorithm, etc. that runs based off of the data extraction methods covered in this blog post, when new unemployment data is created for this data series, it’ll automatically flow through the next time the API query you wrote is called.